WorldDomination.be
cd ~/life && git log | head
Le jour où j'ai compris que je pouvais faire une différence en politique 2016-05-27

Le gras a été gentiment rajouté par une amie.
C'est une histoire que je raconte parfois, au coin d'une table, mais que je n'ai jamais eu le courage de mettre par écrit, je profite d'un instant de motivation parce que je pense qu'en ce moment difficile pour nos actions politiques il est important de partager nos histoires et les récits de réussites. Nous manquons d'ailleurs cruellement d'histoire de nos luttes dans nos communautés.
Cela remonte à l'année 2010, le gouvernement français venait de faire passer la loi Hadopi malgré tous ses déboires et j'avais regardé l'ensemble des débats à l'Assemblée nationale, j'étais particulièrement remonté avec l'envie de faire quelque chose et je venais à la fois de rejoindre la Quadrature du Net depuis 6 mois et de co-fonder la Nurpa dans la même période.
À ce moment là, 4 eurodéputé·e·s venaient de lancer la déclaration écrite numéro 12 qui disait grosso merdo "si la Commission européenne de rend pas publique le texte d'ACTA, le Parlement européen votera contre". Une déclaration écrite est un texte, qui, s'il est signé par la moitié des eurodéputé·e·s en moins de 6 mois, devient une prise de position officielle du Parlement européen (sans pour autant être contraignante).
Le problème c'est que signer ce texte ne peut se faire que de 2 manières : soit dans une salle obscure au fin fond du Parlement européen que personne ne connait, soit avant d'entrer en séance plénière, un moment où les Europudé·e·s ont franchement beaucoup d'autres choses en tête que d'aller signer un papier et bien entendu les planières n'ont lieu que quelques jours une fois par mois.
Pour précision, une déclaration écrite est également quelque chose de fort facile à proposer et par son côté non contraignant elle ne représente pas beaucoup d'enjeux. On a donc le droit à toute une série de déclarations écrites farfelues et sans grand intérêt généralement proposé par des eurodéputé·e·s cherchant un moyen de montrer aux personnes les ayant élues qu'elles ont foutu quelque chose sur un sujet quelconque. À l'époque nous avions trouvé, entre autre, une déclaration écrite proposant une journée internationale de la glace à Italienne artisanale et une autre demandant la déclassification de documents sur les OVNIs.
Mais le sujet était important, nous venions de découvrir ACTA, c'était une horreur et il fallait absolument se battre contre ce désastre annoncé, la Quadrature du Net décida donc de soutenir cette déclaration écrite.
Février 2010, branle-bas de combat, un certain moustachu m'informant via IRC (hé oui) de la situation et me disant basiquement « ça serait bien si tu pouvais trouver quelques personnes et qu'on se rejoigne au Parlement, on a un truc important à faire signer aux Europdéputé·e·s contre ACTA ». Pas tout à fait sûr de vraiment comprendre de quoi il s'agissait, mais ayant pressenti l'importance de l'événement, je me ramenai avec 4-5 personnes - à l'agréable surprise dudit moustachu - ce fut alors le début de la bataille.
Une bataille épuisante qui dura plus de 6 mois à raison de une à deux visites au Parlement par mois. Notre action était simple : aller frapper à la porte des bureaux de tous les députés pour les convaincre de signer la déclaration écrite en leur expliquant à quel point c'était important et espérer qu'ils aillent signer, coller des affiches et distribuer mollement des tracts avant la plénière. Bien souvent nous n'avions à faire qu'aux assistants, les députés étant occupé à d'autres choses, quand ce n'était pas un bureau vide. Ce fut l'occasion pour notre petit groupe (à l'exception du moustachu) de découvrir les rouages de l'advocatie de terrain, les lobbyistes ayant leur propre catégorie de badge au Parlement européen (que nous refusions, nous étions des citoyens, pas des lobbyistes) et les désillusions face aux arguments les plus efficaces ... (« ton chef a signé et a dit de signer alors signe » « tous tes potes ont signé sauf toi » « ton adversaire a signé, si tu le fais pas tu vas passer pour un loser » « roh mais dites les verts, l'ALDE a plus signé que vous ! » mais dit dans leur langue, brefle, la cours de récré).
Je n'irai au Parlement que deux ou trois fois, cette activité étant bien trop stressante pour moi (merci les anxiétés sociales), je me retrouvais bien rapidement à m'occuper de quelque chose de fort important mais plus discret : maintenir la liste de qui avait signé (en plus de trouver des bénévoles et de faire de la coordination). Une tâche bien moins simple que prévu merci l'incompétence techniquement du Parlement européen : il a plus de 700 eurodéputé·e·s, certain·e·s partaient, certain·e·s venaient, les documents de qui avait signé changeaient tout le temps de forme et les députés parfois de nom (en vrai c'était l'époque où le Parlement avait mal inscrit certains noms peu communs en Belgique notamment au niveau des accents) et le terme « opendata » commençait juste à apparaitre. Brefle, un travail pénible, ingrat et peut visible, mais au moins on a pu faire des jolis graphiques (mh ... en matplotlib) qui plaisiaient beaucoup aux journalistes et qui étaient utilisés comme argumentaires auprès de certain·e·s eurodéputé·e·s.
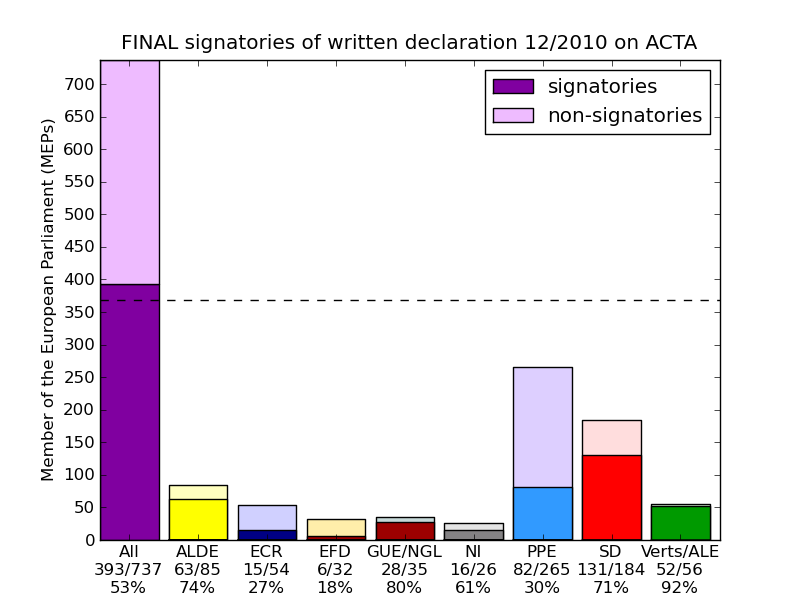
La route fut difficile, nous n'obtenions que peu de signatures au début, ayant préféré viser la droite en premier dans l'espoir que ça ne finisse pas comme "un texte à gauche" que la droite refuserait de signer, les progrès étaient lents et démotivants et le public était totalement désintéressé par cette procédure peu connue, sur un sujet pas encore très en vogue (pas grand monde avait entendu parler de ACTA ou saisit son importance). Ainsi, nos appels répétés à appeler les eurodéputé·e·s restèrent sans grand résultats, ou pire vu la plénière d'avril où nous n’obtiendrons que 27 signatures . Combiné aux 62 et 57 signatures précédentes, cela nous amenait à 146 signatures : très très loin des 369 dont nous avions besoin alors qu'il ne nous restait que 4 plénières. Le moral était au plus bas et les dramas présents.
Ce fut également une période intéressante au niveau de l'invention d'outils d'activisme : à partir des données de qui avait signé (que j'avais extrait de memopol qui à l'époque était une collection de 28 scripts perls écrivant des pages mediawiki et pas le projet qui existe aujourd'hui) nous nous mimes à concevoir des listes papier des eurodéputé·e·s que nous prenions avec nous au parlement européen avec des cases à remplir pour ensuite nous les échanger. Dans le désespoir de l'action « j'inventais » les pads avec la liste de toutes les informations des député·e·s à appeler et des champs à remplir en dessous avec les réponses obtenues (à l'époque le piphone n'existait même au pas au stade d'idée, mais en est une des inspirations) et j'invitais absolument tout le monde à aller dessus, ce fut très ironiquement aussi le moment où nous réalisions que les pads étaient limités par défaut à 14 connections simultanées. Ce fut aussi l'époque où j'ouvris le compte twitter @UnGarage avec le moustachu.
Les plénières suivantes ne furent gère mieux : 39, 34 et 34 signatures soit 253 signatures au total, il nous en manquait 116 pour la dernière plénière, cela nous semblait totalement impossible. Coïncidence heureuse : cette dernière plénière de juillet eu lieu pile pendant les RMLLs 2010 de Bordeaux. La pression était à son comble, nous étions épuisé·e·s et déjà fort occupé·e·s, l'idée était de lancer une scéance d'appels au Parlement avec des téléphones SIP mais rien ne marchait. Après 2-3 jours d’engueulades et de tensions intenses (je me rappelle avoir vue Benjamin consoler une permanente en larmes), nous finîmes par occuper un local et mettre en commun tous les téléphones des gens voulant bien nous les prêter (avec la promesse de remboursement des factures) et à faire un atelier d'appels au eurodéputé·e·s. Ce fut alors l'instant magique de synergie où plein de participant·e·s des RMLLs se sont mis·es à appeler les eurodéputé·e·s à la chaîne. Je me rappelle d'un présentateur radio qui avait particulièrement marqué la salle : après avoir appelé impeccablement bien tou·te·s les Français·es et les Belges, nous découvrîmes qu'il était bilingue lorsqu'il se mit à faire pareil avec tou·te·s Bulgare en bulgare. De son côté, le moustachu qui était lui au Parlement Européen n'était pas en reste et les 4 Europdéputé·e·s à l'origine de la déclaration non plus. Le résultat fut au rendez-vous : nos obtînmes 100 signatures, ce n'était pas les 116 qu'il nous fallait, mais c'était assez pour pouvoir demander une rallonge à la plénière suivante, qui fut obtenue, et nous savions que les 16 signatures manquantes étaient une formalité (et nous les obtînmes par la suite). Nous avions gagné.
Les conséquences de cet événement furent également intéressantes : cette victoire nous avait coûté cher matériellement (tout le budget "actions européennes" de la Quadrature y était passé et nous étions à la moitié de l'année) et humainement et le résultat moyennement intéressant : une déclaration écrite, soit une prise de position officielle mais non contraignante du Parlement Européen. Les effets de bord l'ont été bien plus cependant : les personnes que j'avais embarqué dans l'histoire se sont forcement beaucoup politisées (Bouska par exemple se présentera quelques années plus tard en tant que député pour les Français à l'étranger du Benelux et foutu le bordel sur la question des votes sur Internet), ce fut également une des premières actions politiques de la toute jeune Nurpa qui en a beaucoup grandi et on retrouve également l'influence de cette période dans une partie du tooling de la Quadrature (memopol, piphone) comme dans une partie des méthodes d'actions qui furent et sont encore parfois utilisées.
J'étais personnellement épuisé et ce fut l'un des plus grand soulagement de ma vie mais aussi l'arrivé d'une réalisation : je n'avais de loin pas du tout tout fait tout seul, c'était un travail de groupe avant tout mais j'y avais eu un des rôles centraux et je ne sais pas si ça se serait fait sans moi vu à quel point la victoire avait été difficile à obtenir. J'avais 22 ans et j'avais eu un rôle central dans un groupe qui avait obtenu une prise de position publique du Parlement Européen, c'était possible.
Réflexion : nous n'avons pas de "journalisme" communautaire dans le monde du libre 2015-08-31
Un récrit fréquent dans nos communautés est que nous sommes mauvais en communication, aussi bien entre nous que vers ceux n'y appartenant pas (public non initié, journalistes, politiques et autres), et, force est de constater qu'à quelques exceptions notables (pas besoin de les lister, c'est les structures que tout le monde connait) nous sommes tristement assez proches de nos clichés. Là où, de manière surprenante, nous n'en sommes pas si proches c'est lorsqu'il s'agit d'y trouver des solutions qui marchent pour la majorité. Dire que n'avons rien tenté serait profondément malhonnête, mais depuis mon arrivée dans ce milieu, le discours ambiant n'a vraiment pas évolué de :
- c'est important de communiquer
- tu dois communiquer
- (avec pas mal de la chance mais c'est considéré comme évident en général) voici un ensemble d'outils (blogs/autres), lieux (mailing listes/forums)
Nous avons quasiment 1000 livres pour apprendre à programmer avec/en Python mais nous ne sommes toujours pas foutus d'avoir le moindre livre de référence sur comment communiquer, que ce soit entre nous ou vers les autres et les autres documents sur ce sujet sont rares, pauvres et peu connus. Par conséquent, qui communique dans nos communautés aujourd'hui ? Ceux qui ont appris à la dure, qui ont pris le temps de le faire, aiment peut être le faire, ont peut être une intuition sur comment le faire ou ont peut être été formés pour ... bref, pas grand monde.
« Il suffit donc d'écrire ce livre pour résoudre ce problème ! » vous allez me dire (ou pire « Il suffit donc que tu écrives ce livre » ce qui serait une bien mauvaise idée) ce qui, même si ça serait un grand progrès, serait passer à côté de nombreux problèmes :
- communiquer bien prend du temps, voire beaucoup de temps, du temps que tout le monde n'a pas forcément ou pas envie de mettre là dedans
- communiquer prend aussi de l'énergie, voire beaucoup d'énergie, ce qui est soumis aux même contraintes que le temps
- apprendre à bien communiquer est un processus long et fastidieux
- communiquer est un processus qui peut être intimidant voir effrayant, en particulier dans certaines de nos communautés qui sont connues pour ne pas être tendres voir peuplées de flames war ou trolls velus.
- certaines personnes ne trouvent ça simplement pas amusant voir profondément chiant à faire et dans des activités basées sur le bénévolat et les volontés personnelles ça passe simplement à la trappe (à titre d'exemple : je trouve ça personnellement chiant à faire et un article, celui-ci compris, est véritablement insupportable à rédiger pour moi, je passe plusieurs minutes par phrases)
En effet, quelque chose que l'on apprend en programmation c'est que cela ne sert à rien de se concentrer sur optimiser une partie d'un programme si l'on ne peut qu'attendre au maximum que quelques pourcentages d'amélioration, il faut se concentrer sur les parties où l'on sait que l'on pourra aller bien plus loin. Il est illusoire d'espérer voir un jour l'ensemble des acteurs de nos communautés se mettre à communiquer, aussi bien entre nous que vers l'extérieur.
Alors qu'est-ce qu'on fait ? Est-ce qu'on veut vraiment continuer d'avoir une communauté où la communication (et donc la visibilité) est laissé aux personnes qui ont le privilège d'avoir le temps, l'énergie et le savoir suffisant pour le faire ? Et que tou·te·s les autres vivent dans l'oubli et sans être reconnu·e à leur juste valeur ? (J'ai volontairement mis de côté les projets tellement ultra géniaux (et surtout généralement très vieux) que d'autres se chargent de la communication à leur place, ce sont une minorité) Je pense qu'il va être temps que l'on change de stratégie et que l'on se mette à avoir des personnes ou structures qui se chargent d'une partie de la communication pour les autres.
Mais avant de communiquer bien à l'extérieur, il serait bien de déjà commencer par le faire entre nous. Un copain m'a un jour dit « vous êtes une communauté bizarre, vous n'avez pas d'histoire de vos luttes » Communiquer entre nous, ça permettrait entre autre de nous fédérer, mieux nous connaitre, constituer une histoire commune et de grandir ensemble.
Il y a toutes ces personnes qui se connaissent à peine entre elles et qui font des choses géniales mais pour lesquels bien trop peu sont au courant. Même des structures comme la SNCF sont foutues d'avoir des gazettes internes, mais chez nous, où sont nos "journalistes" de nos communautés ? Où est notre gazette des copains pour les copains par les copains ? Où est-ce que je peux aller pour me tenir au courant de ce qui se passe dans notre petit monde sans être sur 15 ml, 30 chans IRC et 1500 abonnements twitter ? Lire des articles de certains qui ont pris la peine d'aller découvrir de nouveaux projets ou structures, de discuter avec leurs membres et de revenir porter leurs parole et la rendre visible ? Qui me parle des petits, des acteurs locaux, de ceux qui font un travail de fond mais dont on entend pas parler (et pas "yet another" article sur Ubuntu ou Mozilla) ?
Je veux notre journal des copains par les copains pour les copains, qu'on arrête de vivre chacun dans notre coin en s'entre-ignorant, volontairement ou non, et que la visibilité soit l'apanage d'un groupe bien trop petit.
Il existe déjà le Framablog de Framasoft qui se rapproche le plus, à ma connaissance, de ce que je décris (et un grand merci à eux) mais je pense que nous pouvons (et devons) aller bien plus loin.
« Alors, est-ce que tu vas faire quelque chose ? » Je ne sais pas, d'un côté cette réflexion est encore fort jeune (elle date d'avant-hier), le temps est une ressource rare et j'ai bien conscience des problèmes que lancer un "journal" pourrait engendrer (lutte de pouvoir, biais, transmission non fidèle de l'information, appropriation, entre autres), de l'autre, c'est une idée qui mérite d'être creusée et testée sur le terrain et j'ai déjà plusieurs personnes intéressées par l'aventure et je réalise que je fais déjà en partie cela avec HackerAgenda (en Belgique) et la radio et que j'aime beaucoup ça mais que c'est loin d'être suffisant. Affaire à suivre ?
Carte des structures et communautés du monde du libre en Belgique 2015-08-05
Il y a peut, j'ai torché une carte des "structures et communautés du monde du libre" présentes en Belgique, l'idée était d'avoir un résultat rapide pour un événement et comme c'est déjà utilisable (et utilisé : nous l'avons mises sur le site d'Abelli) et que c'est des informations que je n'ai encore vu nul part je vous la remet ici. L'idée à terme c'est de générer tout ça depuis HackerAgenda.
L'url partageable : http://u.osmfr.org/m/48733/
Si vous voulez rajouter des "Structures ou organisations du Monde du libre" dessus contactez moi.
Sur l'exclusion dans les milieux « geeks » 2015-07-22
J'ai bien conscience que les sujets de l'inclusion et de l'exclusion des minorités non présentes dans nos milieux est un sujet régulièrement abordé et que ce poste pourrait sembler être "juste un poste de plus", malgré tout, il s'agit du genre de sujet qui ne sera jamais assez abordé tant qu'il sera d'actualité.
Je suis récemment (bon j'admets, en mois) arrivé à un modèle mental clair sur la question et j'avais envie de le partager.
L'histoire commence généralement par une communauté se décrivant généralement en les termes suivants : « nous sommes ouverts à tous, tout le monde est libre de venir chez nous », ce qui n'est pas nécessairement une mauvaise chose en soit.
Sauf que.
Sauf que survient assez rapidement un problème : certaines personnes ont des comportements excluants. Sans rentrer dans la question de l'invisibilisation et de la non perception ou de la difficulté à percevoir ces comportements excluant pour les personnes en place quand cela ne les vise pas directement, j'aimerai aborder la question de la résolution de cette situation et du principale problème rencontré. Ce principale problème est la première des Five Geek Social Fallacies qui est, je cite:
Geek Social Fallacy #1: Ostracizers Are Evil
Qui pourrait se réécrire ici de cette manière :
On exclue jamais personne, c'est mal
Et c'est le cœur du problème.
C'est le cœur du problème parce que l'on se retrouve face à une incompatibilité : parce qu'on accepte tout le monde on accepte, dans un premier temps, également des personnes aux comportements excluants, qui vont donc exclure ou faire fuir d'autres personnes mais comme on ne les exclue pas [1] car « c'est mal » ™ ces personnes continueront donc leurs comportements et l'on passera donc d'une communauté en apparence « ouverte à tous » à une communauté réservée uniquement aux personnes ne subissant pas ces comportements excluants ou étant prêt à les accepter. Victoire.
La solution pourrait sembler évidente (débarrassons nous de cette fallacy), c'est sans compter la grande résistance d'une « tribu » à faire bouger ses lignes de pensés en particulier sur des règles implicites qui ne sont jamais dites clairement (les personnes n'ayant que même rarement consciences d'être soumises à ces règles), ce qui les rends d'autant plus difficile à attaquer. Heureusement, les choses évoluent dans la bonne direction ces derniers années et même si tout n'est pas tout rose et qu'il y a encore énormément de chemin à faire, cela avance, mais cela prend du temps. Et cela prendrait probablement moins de temps si l'on venait à bout de cette règle non dite (mais ce n'est de loin pas le seul problème, voir : tous les autres mécanismes des oppressions) (et il est important de rappeler que c'est une action importante, voir nécessaire, mais de loin pas suffisante).
Et pour sortir du côté abstrait de ce poste, je vais redire ce que je viens dire de manière beaucoup plus concrète et franche (remarque : quand je vais dire ici "ne peut pas avoir" je vais parler en quantité significative, pas une ou deux personnes).
Une communauté « geek » [2] ne peut pas avoir en son sein :
- des personnes aux comportements sexistes et des femmes
- des personnes aux comportements racistes et des personnes racisées
- des personnes aux comportements transphobes et des personnes « au placard » ou ouvertement trans ou ne se retrouvant pas dans la binarité du genre
- des personnes aux comportements biphobes et des personnes « au placard » ou ouvertement bi
- des personnes aux comportements lesbophobes et des personnes « au placard » ou ouvertement lesbiennes
- des personnes aux comportements homophobes et des personnes « au placard » ou ouvertement homosexuelles
- etc ... (la liste des comportements discriminants est malheureusement fort longue et cette précédente liste n'est de loin pas exhaustive, l'élitisme étant également un de ces comportements fort présent dans nos communautés)
[3]
Il faut donc choisir entre exclure ces comportements (et donc les personnes qui refusent d'arrêter de les avoir) et voir se faire exclure les personnes visées, c'est aussi simple que cela.
À titre personnel, mon choix est déjà fait.
[1] il reste quand même l'option de raisonner ces personnes (quand on réalise qu'ils font cela) mais c'est hasardeux et l'on tombe toujours sur des cas « désespérants » (pour ne pas dire « non solvable ») de la personne qui refuse de reconnaitre son comportement ou le justifiant par une supposé « liberté d'expression » (dont elle ne comprend pas elle même le sens mais qui lui sert d'argument ultime). Et pendant ce temps là, les personnes victimes continuent d'être exclues et les personnes désirant rejoindre la communauté repoussée.
Pour citer une amie : « si je débarque dans un lieu et que je me fais trasher je ne reviens pas et je ne vois pas pourquoi j'aurais la moindre envie de le faire »
[2] Et probablement les autres, mais je ne vais parler que de ce que je connais.
[3] Il va sans dire que l'absence d'une minorité ne peut être utilisé comme argument pour justifier d'accepter des comportements discriminants.
Src (source), l'émission du libre de Radio Campus Bruxelles 2015-07-14

Src (« source ») est une émission de radio sur le thème du logiciel libre, voir du monde du libre, qui passe sur Radio Campus Bruxelles un vendredi sur deux à 18h jusqu'à 19h30 (et est rediffusé le lundi matin à 11h).
Suite au départ d'un des membres moteurs (pour aller sauver Internet) l'émission avait besoin d'énergies nouvelles et donc suite à certaines incitations très incitantes de ce même membre je me suis retrouvé à filer un coup de main à l'émission, d'abord en venant parler de projets sur lesquels j'étais, puis en faisant profiter de mon réseau de contact à Sara (l'animatrice principale) pour l'aider à trouver des invités (et à repasser parfois pour dire des bétises).
Puis, à l'avant dernière émission je me suis retrouvé à co-animer avec Fredux, Sara n'ayant pas pu venir, en interviewant l'invité et à la dernière émission à commenter sur les sujets d'actualités je pense que je fais définitivement partie de l'équipe.
La prochaine saison (à partir de septembre) s'annonce assez chouette : l'équipe s'est agrandie et est bien plus stable et des discussions que nous avons eu il y a beaucoup de chance pour que l'on passe de « Souce, l'émission du logiciel libre » à « Source, l'émission par et pour le monde du libre » avec une approche bien plus inclusive, communautaire et ouvert à la collaboration (l'émission que tu fais toi même) en en faisant un porte voix pour les acteurs locaux et en invitant les gens à se saisir de cette opportunité en nous proposant de venir parler de chez nous de ce qu'ils font (quand on ne les aura pas déjà démarché nous même). Ceux qui suivent réaliseront que c'est ce qu'on s'était déjà mis à faire en grande partie mais là cela deviendra explicite et nous communiqueront sûrement comme ça.
Voici les podcasts des émissions où j'étais présent :
10 juillet 2015 : Nurpa, hacking team, RMLL 2015
26 Juin 2015 : Fo.am et F/LAT (des collectifs d'artistes numériques)
1 Mai 2015 : Compte rendu d'Associalibre, femmes dans l'informatique, Neutralité du Net à l'Europe
13 Mars 2015 : YUNOHOST, Rapport Reda
27 Février 2015 : Abelli et AssociaLibre
13 Février 2015 : Vie privée avec le gros data et Neutrinet
[old] Présentation de la Brique Internet à Radio Campus 2015-07-12
En vrai c'est l'annonce pour un événement de Neutrinet de présentation de la Brique Internet mais cela marche aussi comme présentation de la Brique.
C'était le 5 juin et c'était notre première annonce publique du lancement de la Brique Internet chez Neutrinet.
Merci à Déborah, Fredux et campus <3
Compte rendu du premier meeting technique de la Brique Internet 2015-07-07
Ce lundi 6 juillet nous avons eu notre premier meeting technique sur la brique internet.
Dans les grandes lignes:
On aimerait automatiser la build des images pour la brique, chez Neutrinet on aimerait être capable d'arriver au point où on construit une image complète entièrement pre-configurée par membre et qu'on a plus juste à copier. Pour l'instant on a encore des problèmes techniques de virtualisation. (Remarque: après la réunion quelqu'un a suggéré de foutre une board olimex en DC pour pour l'utiliser comme endroit de build)
Retour sur l'install party de neutrinet de jeudi dernier. Ça s'est en gros très bien passé, la qualité était au rendez-vous (pas de bugs et bon encadrement), mais pour l'instant une personne (à l'aise dans ce processus) peut difficilement envisager de faire plus de 2 installations en une soirée. On a donc besoin de former plus de monde pour nous aider.
Clarification de comment communiquer avec YUNOHOST pour les retours utilisateurs et probablement création d'une liste d'applications spécifiques à la brique pour les utilisateurs de la brique mais uniquement pour les applications vraiment spécifiques, les autres applications doivent finir upstream.
Retour d'expérience de kload sur sa propre brique, il a basculé tous ses mails dessus, entre autre. L'usage de DKIM et SPF permet vraiment d'attendre un niveau de serveur mail vraiment sympa sans de problèmes chez les gros chiants (cf google et microsofts). C'est malheureusement pas encore intégré dans YUNOHOST/nos processus d'installations mais il y a volonté de le faire à l'avenir.
Vous pouvez retrouver le pv en entier ci dessous:
Little utility to add an event to Neutrinet's wiki 2015-07-07
In my broad quest to automatise/optimise everything boring in my life (and having great reason to procrastinate doing it), my latest victim was the action of adding an event to Neutrinet's wiki.
It's a stupid action, doesn't take that long, but it's plain boring and unfunny to do: it's on mediawiki using semantic form which gives a pretty bad UI. So it's annoying enough for me to procrastinate it for too long and I was also in need of finding a reason to procrastinate the other important things I was in need to do. I also wanted to test robobrowser which is a modern version of mechanize and that uses BeautifulSoup, a python html parsing lib that I really like.
Spoiler: robobrowser has now replaced mechanize for me, it's pretty cool and just do what I want in a nicer way than mechanize.
And because the other things I was procrastinating were boring (while kinda important), I took the time to make this script super nice and fancy.
Here its help page:
usage: add_event [-h] -d D [-m M] [--hour HOUR] [-y Y] [--min MIN]
[--location LOCATION] [-t TITLE]
optional arguments:
-h, --help show this help message and exit
-d D date (default: -)
-m M month (default: -)
--hour HOUR hour (default: '7')
-y Y year (default: -)
--min MIN minutes (default: '30')
--location LOCATION location (default: '123 rue royale 1000 Bruxelles
Belgique')
-t TITLE, --title TITLE
A classical session (the event name is automatically created based on the wiki's data because it's also boring to do by hand):
$ add_event -d 24
I'm about to create the event 'Meeting 2015/10' on 19:30 24/7/2015 at '123 rue royale 1000 Bruxelles Belgique'
Continue? [Y/n]:
Login into mediawiki:
Username: bram
Password:
I've also used argh which is, by far, my favourite and easier to use python lib to handle cli arguments.
Source code of the script: https://github.com/psycojoker/neutrinet_add_event
Conference au POOP 2014 : HackerAgenda aidons nous a mieux nous parler 2015-01-13
Une conférence que j'ai donné au POOP 2014 à Paris en Juin dernier sur HackerAgenda, un projet d'agenda automatisé aggregant de très nombreuses sources d'événements pouvant intéresser les hackers en Belgique.
L'idée derrière étant d'essayer d'améliorer la situation "plein de gens font plein de choses géniales mais personne ne se connait".
Dans cette conférence je parle de 2 approches face à cette situation (dont HackerAgenda) et j'essaie de trouver des gens motivés pour lancer un HackerAgenda pour la France.